DeepSeek-V3.2: The Open-Source AI Model That Challenges GPT-5
DeepSeek-V3.2: The Open-Source AI Model That Challenges GPT-5
Just when Silicon Valley thought it had cornered the market on absurdly expensive, closed-source AI models, a Chinese research lab dropped a bombshell that's been quietly terrorizing leaderboards across the AI industry. Meet DeepSeek-V3.2—a model that costs pennies to run and somehow manages to give GPT-5 a genuine run for its money.
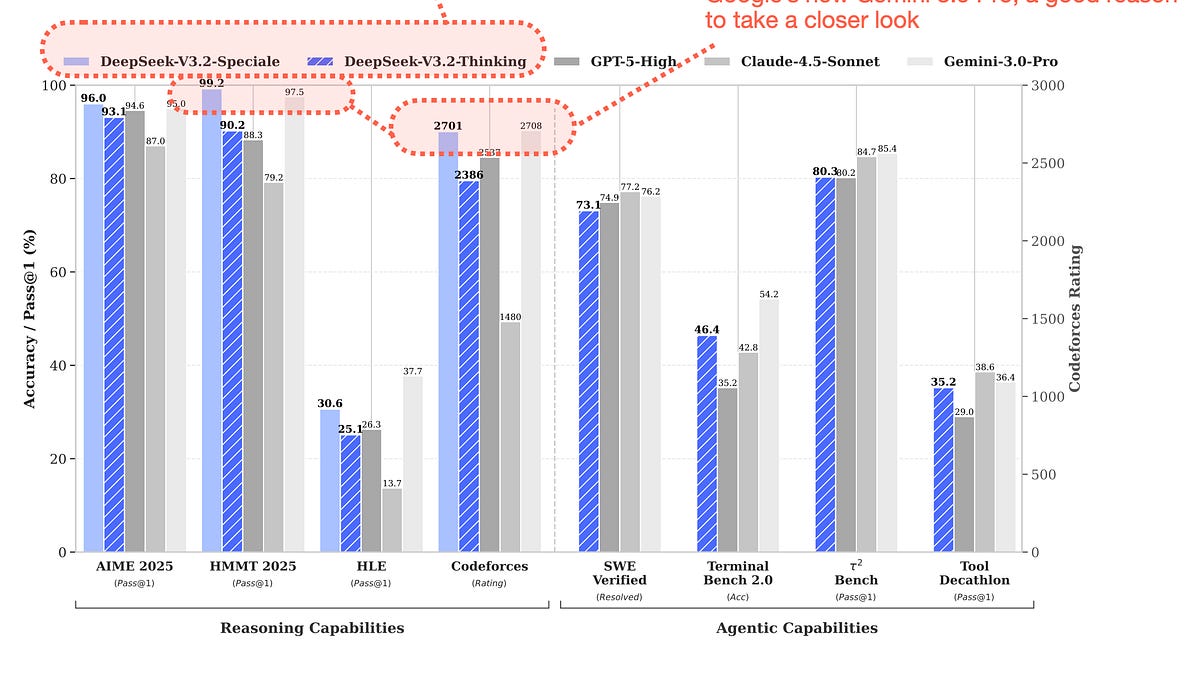
Figure 1: DeepSeek V3.2 benchmark performance vs proprietary models. Source: Sebastian Raschka, PhD
The Open-Source Lightning Rod
Here's the setup: DeepSeek-V3.2 comes in two flavors—V3.2 Thinking for production workflows with tool-use capabilities, and V3.2 Speciale, a specialized reasoning variant that sacrifices formatting for maximum raw intelligence. Both pack a staggering 685 billion total parameters (though only 37B activate per token—nice efficiency trick there) and sport a 128K-163.8K token context window. Crucially, they're both MIT-licensed open weights.
Compare that to GPT-5's "here's an API key, trust us with your data" business model, and you start to see why enterprise architects are getting twitchy. DeepSeek's sparse attention mechanism drops computational complexity from quadratic to near-linear, meaning long-context processing becomes dramatically cheaper and faster. This isn't just incremental improvement—it's architectural innovation that challenges how we think about attention costs at scale.
Performance That Actually Matters
The most dangerous part? It actually performs. According to DeepSeek's own technical reports and multiple independent analyses, V3.2 Thinking achieves parity with GPT-5 and Gemini 3.0 Pro on several key benchmarks. The Speciale variant goes further, reportedly outperforming GPT-5 in complex reasoning tasks like AIME 2025 and IMOAnswerBench.

Figure 2: Tool-use benchmark performance showing V3.2 competitive with leading closed models. Source: Shadeform
We're talking about reasoning benchmarks that GPT-5.2 itself only recently mastered, yet here's an open-weight model matching or beating those scores. The enterprise implications are immediate: why pay premium per-token rates for a closed model when you can self-host something competitive for a fraction of the cost?
The Real Story: Enterprise Adoption and Hardware Politics
Recent developments show DeepSeek isn't just winning benchmarks—it's winning infrastructure battles. Reports indicate China has cleared DeepSeek to purchase NVIDIA H200 chips, subject to regulatory conditions. This signals massive scale-out capacity that makes the economics even more compelling for global enterprises.

Figure 3: Reasoning benchmark where V3.2 Speciale outperforms GPT-5 and Gemini 3.0 Pro. Source: Shadeform
Shadeform's recent analysis shows H200 GPUs delivering the best cost-to-performance profile for V3.2 deployment, with token costs dropping to $0.0026 per 1K tokens at high concurrency. Compare that to closed-source API rates, and suddenly your CFO cares about AI architecture decisions.
Microsoft President Brad Smith has explicitly warned that DeepSeek's open-source, low-cost approach poses a genuine threat to U.S. enterprise market share. This isn't FUD—China combining government-backed acceleration with genuinely competitive models creates a dual advantage in price and deployment speed that American tech giants are scrambling to match.
The Tradeoffs Nobody's Talking About
Let's be real: V3.2 isn't perfect. The Speciale variant abandons tool-use and structured output for pure reasoning power—great for math competitions, problematic for production pipelines that need JSON responses every time. The standard Thinking model keeps agentic capabilities but sacrifices a fraction of peak reasoning performance.
And yes, there are the elephant-in-the-room questions about data residency, given the PRC storage policy in DeepSeek's terms. Enterprise legal teams will have feelings about that. But for pure performance-per-dollar engineering? V3.2's value proposition is increasingly undeniable.
What This Means for the AI Landscape
DeepSeek-V3.2 represents the first genuinely competitive open-weight challenger to GPT-5's dominance. It's forcing a market split: pay premium for closed-source convenience and ecosystem integration, or self-host with real tradeoffs but dramatic cost savings.
For developers building production systems, the choice is no longer "which closed model do we use?"—it's now "closed, open-weight, or hybrid?" That's a fundamental market shift that's been accelerating in early 2026, and V3.2 sits right at the center of it.
The open-source community keeps delivering models that shouldn't be this good at these price points. GPT-5 remains the polished, production-ready standard for many enterprises. But the gap has closed enough that the question of "why not self-host?" is now one CFOs will actually ask.
DeepSeek-V3.2 isn't just another model—it's proof that the frontier model market has competition from the open-weight side that can't be ignored. How OpenAI, Google, and Anthropic respond will determine whether 2026 becomes the year open-source fundamentally reshapes enterprise AI adoption.
Sources:



Comments ()