AI Finally Got Eyes: Why Multimodal Intelligence Is About to Change Everything (Again)

Remember when chatbots were the cutting edge? Cute times. We're now witnessing AI that doesn't just read your words—it watches your screen, listens to your voice, and actively explores images like a digital detective with way too much coffee and zero privacy boundaries. Welcome to the era of Multimodal AI, and it's moving fast enough to make your head spin. Or, well, process images and text simultaneously enough to make previous systems look like they were operating on dial-up.
What's Actually New (Because We've Heard This Hype Before)
Here's the thing: multimodal AI isn't exactly breaking news. Google's been building multimodal into its DNA for what feels like a decade, and GPT-4o has been processing images alongside text for ages. But what's changed in the last 72 hours is something genuinely different—active vision.

Image: Aesthetic visualization from The Living Edge showcasing multimodal architecture with visual, textual, and potentially audio processing pathways working in concert.
Google's Gemini 3 Flash and Moonshot's Kimi K2.5 have shifted from passive image processing to what's being called "agentic vision." Instead of just describing what they see in one static frame, these models can now zoom, pan, and run analysis tools to actively investigate visual data. Think of it less like looking at a photo and more like a radiologist who can adjust magnification, run additional tests, and focus on specific regions of interest.

Image: Animated GIF demonstrating active vision capabilities, showing how models can dynamically explore image regions rather than processing fixed frames.
Why Active Vision Actually Matters (Beyond the Marketing)
The practical implications here are genuinely significant. Consider medical imaging: previous multimodal systems could describe an X-ray generally. New agentic vision can zoom into specific regions, identify subtle anomalies, and correlate findings with patient records in real-time. Google's AMIE system demonstrated this in clinical diagnostics, where their AI agent can request, interpret, and reason about visual medical information during consultations, achieving performance that matches or exceeds primary care physicians in simulated scenarios.
The same principle applies to enterprise workflows: pointing an AI at a 50-megapixel satellite image or a complex dashboard and asking it to find specific details becomes viable when the model can actively explore the visual space rather than trying to process everything at once. It's the difference between reading a book and speed-reading with a highlighter and search functionality built in.
World Models: When AI Starts Simulating Reality
Perhaps even more intriguing than active vision is the emergence of world models—systems that don't just generate content but understand and simulate physical reality. Project Genie from DeepMind generates interactive 2D worlds you can play in real time, with the model predicting frame-by-frame reactions to your inputs. It's hallucinating a working game as you go.
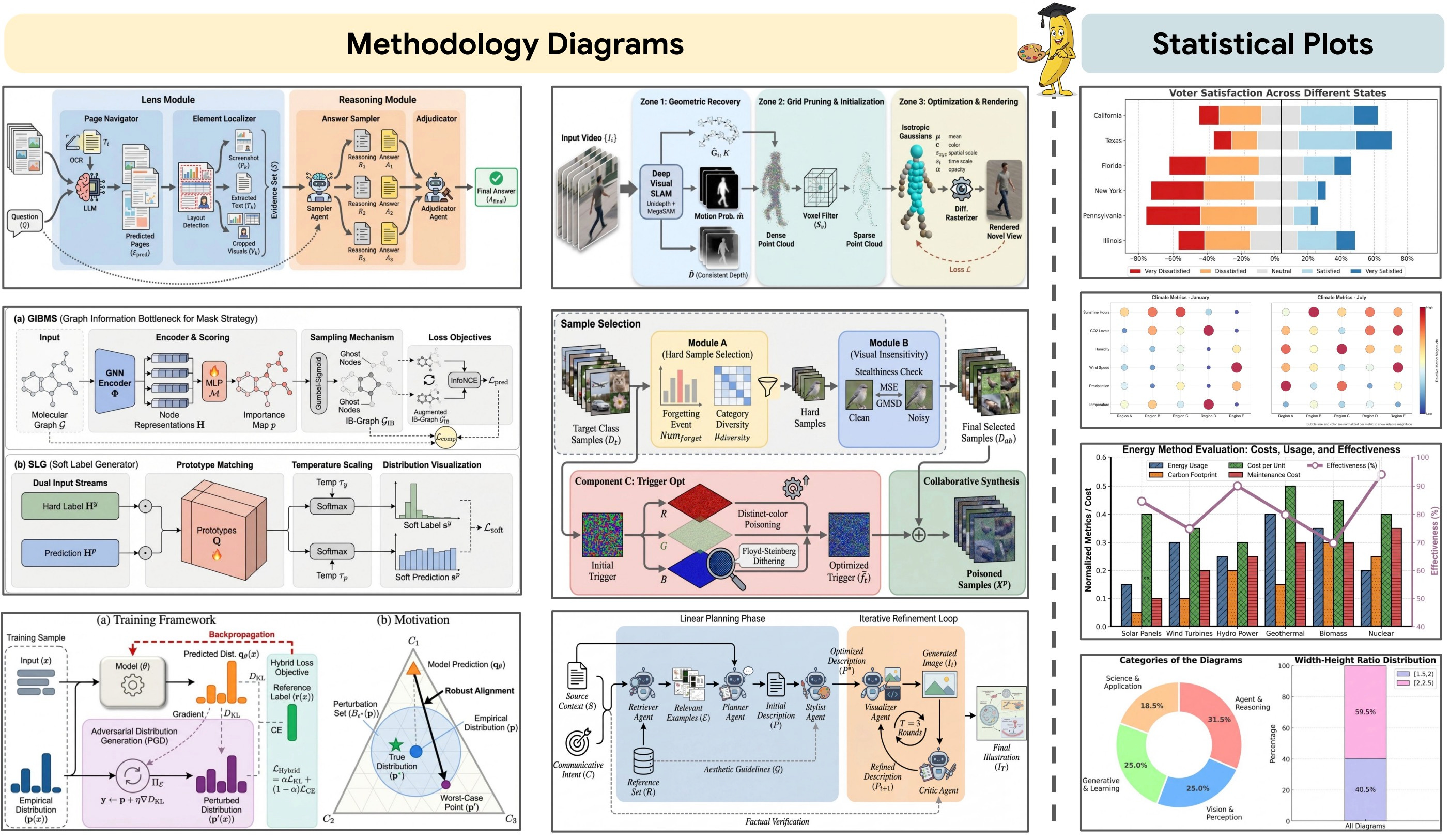
Image: PaperBanana workflow visualization demonstrating how agentic AI frameworks coordinate multiple specialized agents to complete complex tasks, here applied to academic illustration automation.
EgoWM takes this concept further for robotics, simulating humanoid actions from a single first-person image so effectively that a robot can "imagine" its movements rendered as a painting—across visual domains it has never actually seen. Drive-JEPA applies world modeling to autonomous driving, predicting abstract representations of road scenarios rather than every individual pixel, because, as one research paper succinctly noted, "cars don't need to model leaves and shadows, just other vehicles and pedestrians."
The Economics Behind the Innovation
nGartner's 2025 AI Hype Cycle positions multimodal AI as a mainstream innovation technology within the next five years, which is analyst-speak for "this is going to be absolutely everywhere and your company needs to figure it out yesterday." The market projections are substantial, with estimates suggesting the multimodal AI market could expand by $300-500 billion in total addressable market opportunity by 2030.
The competitive landscape is intensifying rapidly. Google's Gemini 3 boasts a 2 million token context window with integrated agentic reasoning, positioning it as a direct competitor to anticipated GPT-5 capabilities. Early benchmarks show Gemini 3 achieving 88% MMLU accuracy with projected improvements in cross-modal reasoning of 12-18% over previous generation models.
What This Actually Means for You (Yes, You Personally)
The real story here isn't about which tech giant wins the multimodal arms race—it's about what becomes possible when AI can simultaneously process text, audio, and visual information with genuine understanding rather than concatenation:
- Healthcare: Diagnostic systems that can examine medical imaging, listen to patient descriptions, review written records, and request additional information—simultaneously.
- Enterprise: AI that can watch your screen, understand context from meetings, and take action based on combined understanding of what it sees, hears, and reads.
- Creative tools: Systems that generate video with synchronized audio and visual effects from a single prompt, rather than requiring post-production stitching.
- Education: AI tutors that can see your work, hear your questions, and provide feedback that accounts for both modalities.
The Bitter Truth We're All Ignoring
Here's the uncomfortable part nobody's talking about: as multimodal AI becomes more capable, the gap between what it can technically do and what we're socially prepared for it to do widens significantly. Active vision means AI can watch everything it has access to. World models mean AI can simulate scenarios with concerning fidelity. The technical capability is outpacing our ethical frameworks, governance structures, and perhaps most importantly, our individual understanding of what we're actually agreeing to when we deploy these systems.
The innovations of the past week are genuinely impressive. Kimi K2.5's parallel execution running 4.5x faster than sequential approaches solves latency problems that have plagued agentic workflows. Google's investment in TPU v5p optimizations enabling sub-second latency makes real-time enterprise applications genuinely viable. These are real technical achievements that will transform how work gets done.
But maybe, just maybe, we should spend at least as much energy thinking about the implications as we do celebrating the capabilities. The future isn't just about making AI that can do more—it's about making AI that does more in ways that actually serve human interests rather than just efficiency metrics.
The Bottom Line
Multimodal AI has graduated from experimental feature to foundational technology. The shift from passive to active vision, combined with the emergence of world models that can simulate physical reality, represents a genuine inflection point. We're moving from AI that can describe our world to AI that can explore, understand, and potentially manipulate it.
The question isn't whether multimodal AI will transform industries—it already is, from healthcare diagnostics to autonomous driving. The real question is what kind of relationship we want to have with systems that can see, hear, and understand us better than we understand ourselves. That conversation needs to happen alongside the technical development, or we're going to find ourselves living in a world shaped by AI capabilities that nobody actually signed up for.
Technical excellence without thoughtful deployment is just expensive trouble waiting to happen. The past week showed us what multimodal AI can do. The coming weeks will show us whether we're wise enough to implement it well.



Comments ()